Enable latency routing in the Requesty Console.
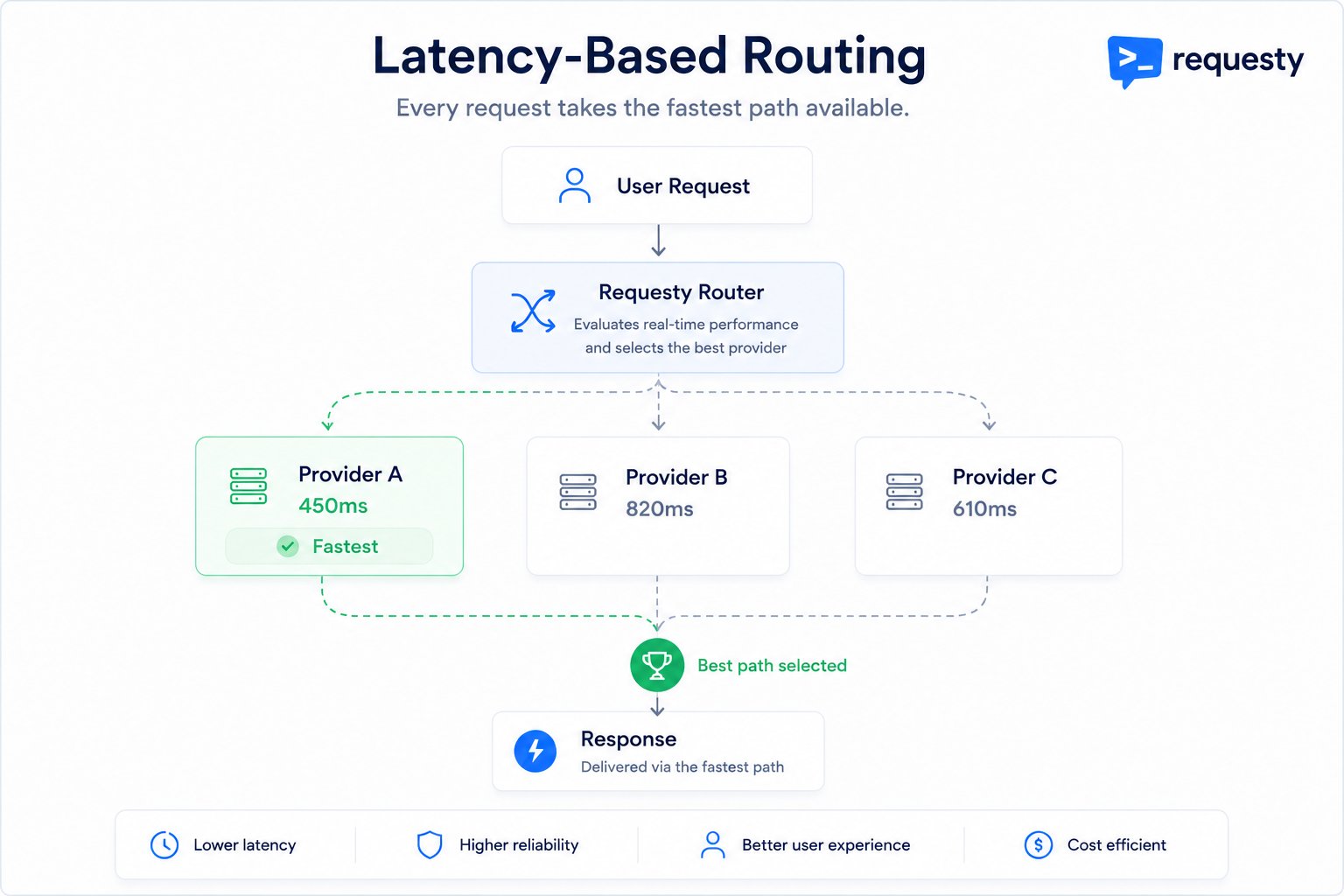
How It Works
Measure live performance
Requesty continuously measures how every model in your policy is performing right now, across all traffic flowing through the router. Recent requests count more than older ones, so the picture reflects current conditions rather than yesterday’s averages.
Score each candidate
When a request arrives, the router scores every model in your policy. The score accounts for how fast each one starts responding, how quickly it generates the rest of the output, and how much of each it has actually observed recently. Models with little recent data are scored optimistically so they still get tried.
Benefits
Fastest Responses
Always use the quickest model available.
Automatic Adaptation
Router adjusts when model performance changes.
No Manual Tuning
Latency optimization happens automatically.
Regional Optimization
Automatically prefer nearby endpoints.
Creating a Latency-Based Policy
Create the Policy
Go to Routing Policies, click Create Policy, and select Latency as the policy type.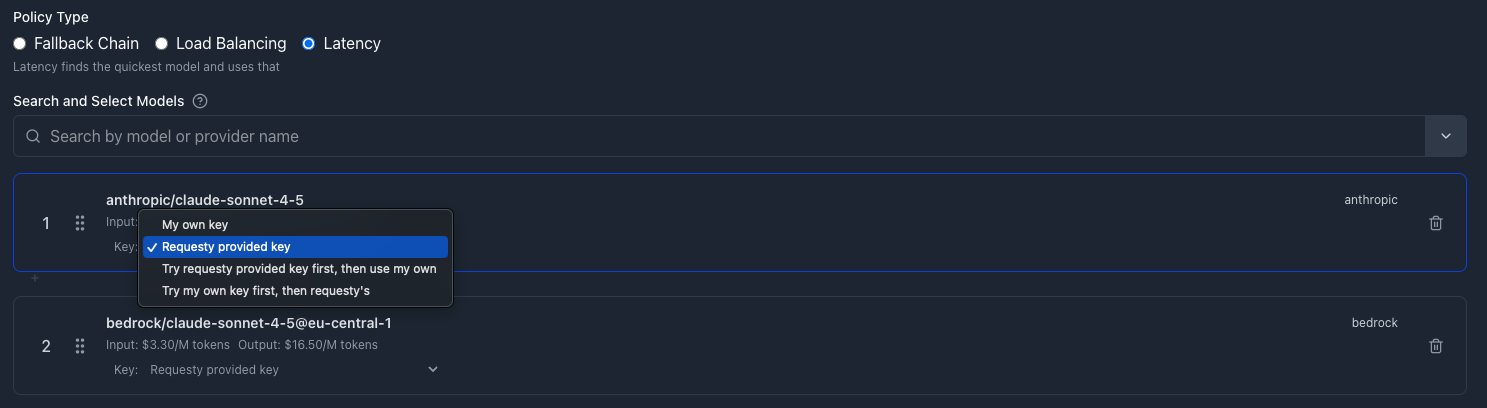
Select Models
Add your models. For example:
The router will automatically choose whichever is faster at request time.
| Model | Description |
|---|---|
anthropic/claude-sonnet-4-5 | Direct API access |
bedrock/claude-sonnet-4-5@eu-central-1 | Regional endpoint |
How Latency Tracking Works
Requesty measures both time-to-first-token (how fast a model starts responding) and generation speed (how fast it produces the rest of the output), so a model that starts quickly but generates slowly does not get an unfair advantage.| Metric | Description |
|---|---|
| Time-to-first-token | Time from request sent to first token received |
| Generation speed | How quickly tokens are produced after the first one |
| Request size | Performance is tracked separately for small and large requests, since they behave differently |
| Scope | Measured across all traffic on the router, so even your first request benefits from data others have already generated |
| Window | A rolling window of recent requests (about the last hour), weighting newer requests more heavily |
Models with little recent latency data are still tried from time to time so the router can learn how they perform. After a handful of requests, it has enough signal to route them accurately.
Key Selection Strategies
For each model, you can configure which API key to try first:| Strategy | Description |
|---|---|
| Requesty provided key | Use Requesty’s managed keys only (default) |
| My own key | Use your BYOK credentials only |
| Requesty first, then BYOK | Try Requesty’s key first, fall back to BYOK |
| BYOK first, then Requesty | Try your key first, fall back to Requesty |
Use Cases
Regional Optimization
Regional Optimization
Route to the fastest regional endpoint:
Users in Europe automatically get
| Model | Region |
|---|---|
anthropic/claude-sonnet-4-5 | Global |
bedrock/claude-sonnet-4-5@us-east-1 | US East |
bedrock/claude-sonnet-4-5@eu-central-1 | Europe |
bedrock/claude-sonnet-4-5@ap-southeast-1 | Asia Pacific |
eu-central-1, users in Asia get ap-southeast-1.Provider Performance
Provider Performance
Let the router pick the fastest provider:
If OpenAI is experiencing slowdowns, traffic shifts to Anthropic or Google automatically.
| Model |
|---|
openai/gpt-5.2 |
anthropic/claude-sonnet-4-5 |
google/gemini-2.5-pro |
Cost + Speed Optimization
Cost + Speed Optimization
Combine similar-priced models and route to fastest:
All three are low-cost. Requesty picks whichever responds fastest.
| Model |
|---|
openai/gpt-4o-mini |
anthropic/claude-3-5-haiku |
google/gemini-1.5-flash |
Combining with Other Policies
Latency routing works great with load balancing and fallback.| Combination | How It Works |
|---|---|
| Latency + Load Balancing | Each sub-policy uses latency routing, parent policy does A/B testing |
| Latency + Fallback | Try latency-optimized policy first, fall back to known-good model if all fail |
Monitoring Latency
Open Performance Monitoring
Go to Performance Monitoring.
FAQ
What if a model has no latency data?
What if a model has no latency data?
Models without recent data are scored optimistically, so they get tried from time to time to gather performance signal. Once they have measurements, they compete fairly against everything else in the policy.
Does latency routing consider cost?
Does latency routing consider cost?
No. Latency routing only considers speed. If you want cost optimization, use load balancing to prefer cheaper models, or manually order a fallback chain by price.
Can I force a specific model for some requests?
Can I force a specific model for some requests?
Yes. Instead of using the latency policy, pass a direct model name (e.g.,
openai/gpt-5.2) for requests where you need a specific model.How often does latency data update?
How often does latency data update?
Continuously. Latency metrics are updated after every request. The router uses a rolling average of recent requests to smooth out spikes.
What happens if the fastest model fails?
What happens if the fastest model fails?
Latency routing tries models in speed order. If the fastest model fails, it tries the second-fastest, and so on.
Can I see which model was selected?
Can I see which model was selected?
Yes. Check the response headers or request logs in Analytics. You will see which model handled each request.
Unlike load balancing, latency routing does not pin a user to one model. If you want the same conversation to keep hitting the same provider (for prompt cache reuse), pass a
trace_id: the router keeps its ordering stable for requests that share a trace, while still adapting across new conversations.